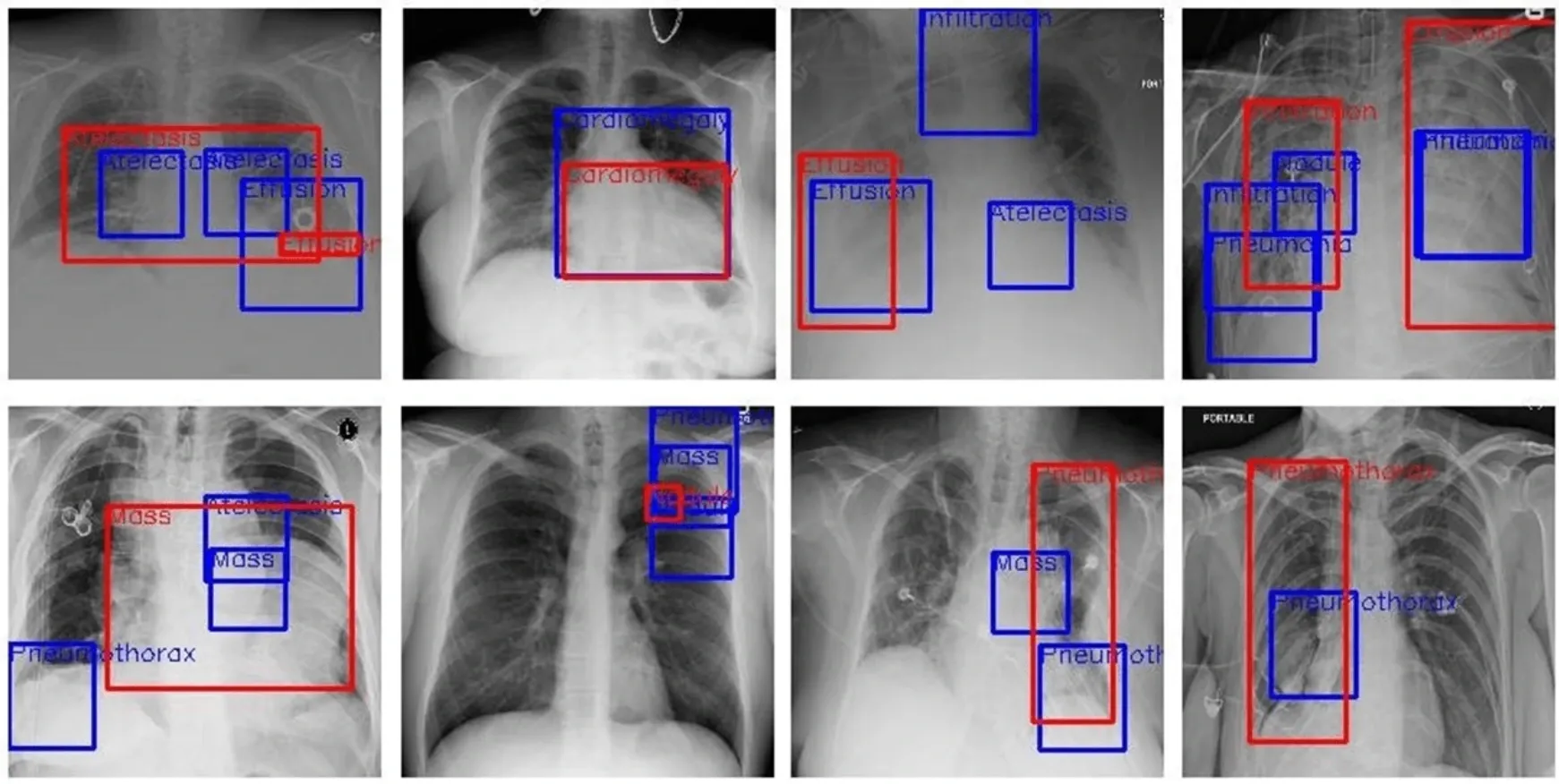
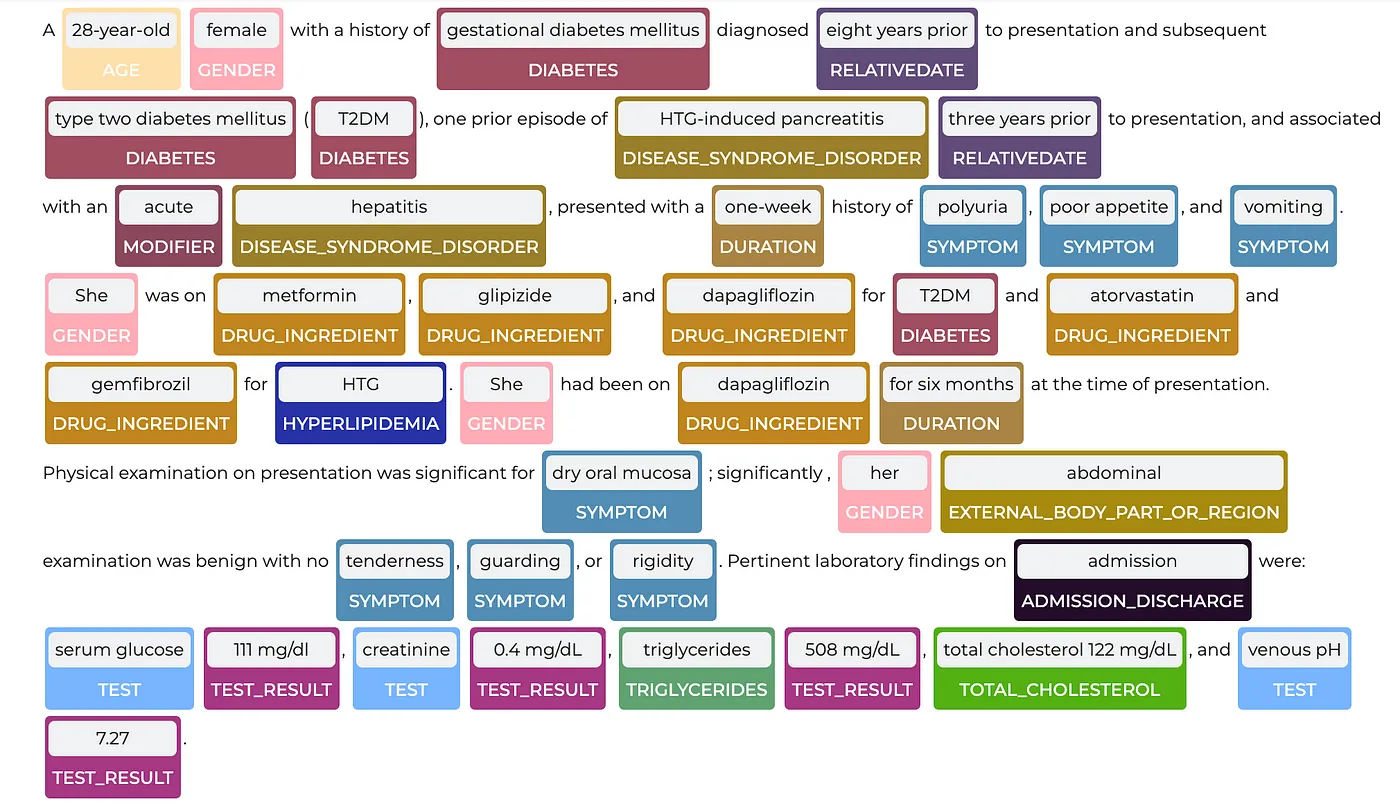


Transform complex multi-cancer clinical trial protocols into consistent, structured eligibility criteria that a verifier model could evaluate.
Scaled a team of M1-M4 medical students trained on a standardized workflow to interpret oncology datasets and handle response discordance through consensus review.
• 94% inter-rater agreement across 6 cancer types
• Standardized data format enabled single survey template
• 72-hour turnaround with zero-cost expert replacement
• Model accuracy improved from 67% to 91% on eligibility determination
Train a PHI detection model using thousands of real clinical documents, requiring fast, compliant annotation from reviewers who understand clinical context and terminology.
Built a 300-person team of US-based medical students using a secure iOS workflow. Reviewers highlighted and tagged all PHI entities in clinical notes and transcripts with entity-level classification and clinical context preservation.
• 98% PHI detection recall with clinically-aware annotators who caught context-dependent identifiers
• 3x faster throughput via mobile-first workflow enabling flexible scheduling
• Zero compliance incidents with US-based, HIPAA-trained workforce and BAA-compliant infrastructure
• <48 hour backfill for dropped annotators maintained consistent delivery

Evaluate consumer models for bias, unhealthy beliefs, ability or refusal to help with violence or self-harm, removal of hate speech, and manipulative content.
RLHF: Developed user personas and high risk scenarios. Established metrics and benchmarks using NIST AI RMF & ISO/IEC 42001. Clinical psychologists reviewed outputs, provided severity ratings, feedback and suggested better responses to each scenario.
Red Teaming: Designed prompts to bypass guardrails and trigger unwanted responses. Clinical psychologists logged failures, clustered by pattern, and assigned severity
• Harmful response rates drop from 40% to under 5%
• Decreased critical and high severity response rates by over 70%
• Established workflows for continuous monitoring and feedback
Create a durable reasoning benchmark that exposes failure modes in frontier models without becoming obsolete after one training cycle—requiring prompts that are human-solvable but consistently difficult for LLMs.
Developed adversarial evaluation methodology using backward-engineered prompts from stable facts across academic, historical, and legal domains. Each prompt required 3/3 failure rate across leading models, verified ground-truth answers with citations, and detailed scoring rubrics before dataset inclusion.
• 100% prompt durability - all questions remained challenging across 4+ model generations
• 85%+ human solve rate vs. <33% initial model accuracy, validating adversarial effectiveness
• Production-ready evaluation suite with answer keys, rubrics, and automated verification infrastructure
• Enabled systematic tracking of reasoning improvement across model releases

.jpg)
Hire 85 Internal Medicine physicians with experience in Women's Health. Licensed in all 50 states. At least 1 physicians per state. Available between 15-40 hours per week with coverage on weekends and nights. At least 1 yr of experience in telehealth. Native or professional English, and nice to have Spanish. Physician rate: $150/hr.
Sourcing & Verification: Over 300 Internal Medicine physicians applied and completed ID, board and license verification. 110 physicians matched criteria for skills and experience. 90 physicians interviewed for soft skills, English proficiency, and shared with client for hiring.
• 90 matched candidates in 2 weeks
• Estimated 450 hours saved working with Folio for initial sourcing
• Estimated $30,000 saved working with Folio for initial sourcing
• Estimated over $100,000 saved working with Folio for subsequent sourcing and back office operations for 1099 contractors

